
Note:
This is something I worked on for one of my project. In the example I will be decoding the captch of VTU website, which is an University for Engineering courses and has captcha at results portal.
The approach detailed in this article is not a general purpose solution, but can be used for captchas of similar complexities.
This is NOT a ML based solution.
Preface
VTU results page is known for its speed, reliability, performance and user-friendly interface. Or rather the lack of it. Every semester, even though the org knows exactly how many students will be looking forward for their results, it always fails to scale up their servers to cater to this load. It usually takes hours to get your results after they are released. The webpage does not load, the result request is not queried, or the whole website just crashes. And moreover the results of the previous semester will be wiped out before the new ones are uploaded. So there is no way for a student to get his last results (screenshot is the only option) or rather all his sem results in one place.
I wanted to create a website that would store these results, of all semesters and would display them on request. And this also falls under the web-scraping domain, which I wanted to do a project in. So I started to work on getting the details required, but the problem was the form to query the results also had a CAPTCHA.
So in this article i will be explaining the steps I took to decode them and convert to text so that I can get whats behind it.
The CAPTCHA image
The image is not that complex when compared to other google captchas that has a lot of features like warping, tilt, blur, skew etc.. to consider in the text that has to be decoded.
Saying that, this took a bit of work as well, since I decided to solve this without additional libraries, just simple python. Using open source projects Tessaract or other OCRs will be a bit of overkill for this Image.

I saved a few such Images and found that the text is always at the center and in green color. And the entire image is covered in static/noise.
Initially I thought of extracting Green from the RGB matrix of the image, since the text that i want is entirely in green. But this didn't work as there was a lot of noise pixels that were in green also. What worked is a simple thresholding of the image.
Converted my image to monochrome/binary with appropriate threshold value to select between black pixel or white pixel worked far better than I had imagined.
Output of this thresholding captcha -


Now that the text is clear, next is the OCR part of actually converting the contents on the image to usable text. Before that I had saved bunch of images and there was a pattern emerging, all the characters occupied same space at the middle of the image. And to visualize it better, I used this web-tool to convert the pixels to text characters and saved it.
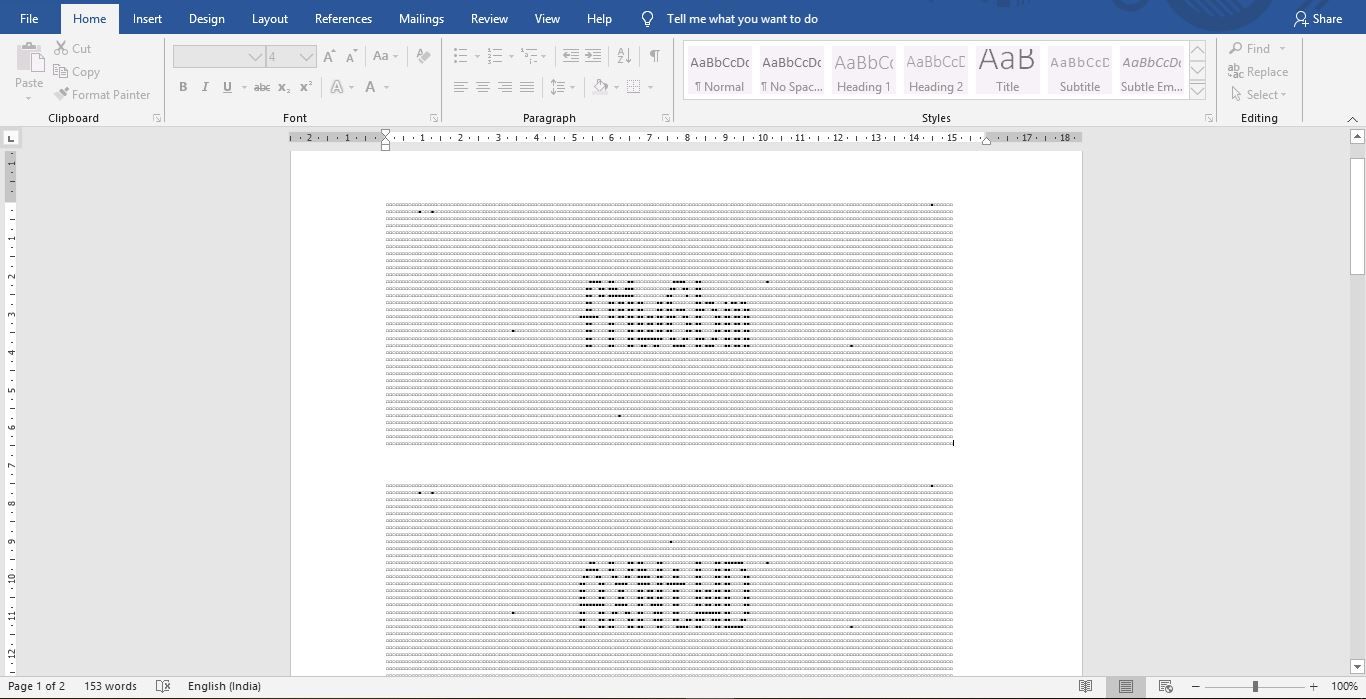
Some points that came out about this captcha now-
- The text is always at the center and starts at
[60,11]ie. top left corner and ends at[113, 23]ie. bottom right corner. - Each character in the text occupies exactly the same number of pixels ie- same height and width. Which means a rectangle mask can be used to extract each individual char. The dimensions of this mask
8 X 12.
Manual Labeling
Now that we know the dimensions and position of the charterers in the image and we have removed the noise, the next step is to isolate each character and start labeling. This is one step that is not automated, but is also one-time requirement.
Using a small script, I downloaded a bunch of captchas and chopped them down to individual characters and saved each one with different number as file name.
During the process I found out that characters - I L O i l o 1 0 are not used. Which is actually quite obvious when you think about it, they are hard to distinguish from each other in several fonts.
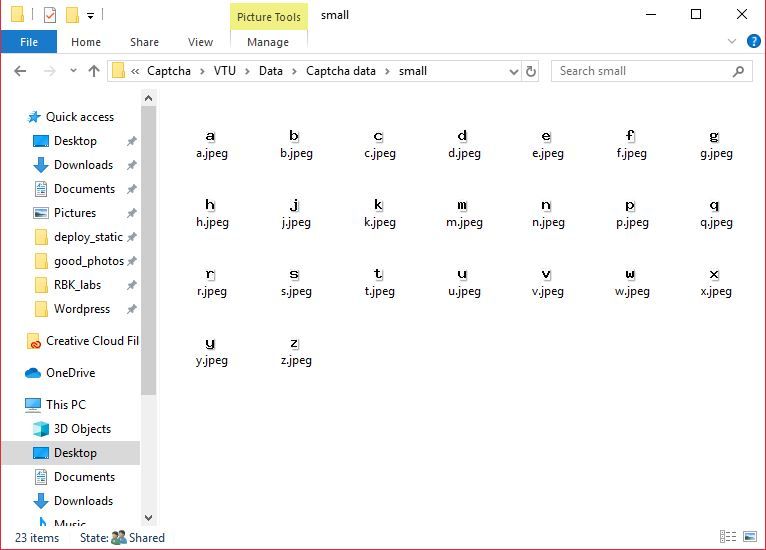
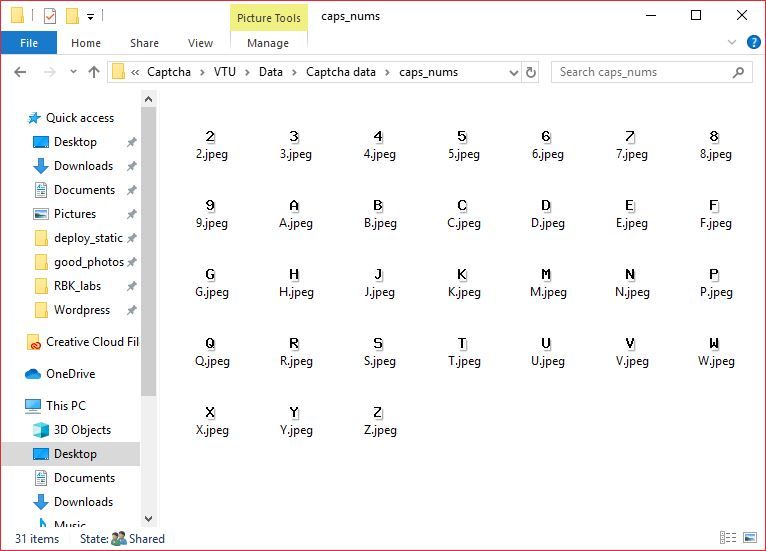
Turning into Dataset
Converting this set of labeled Images into usable dataset is actually pretty simple. All you have to do is store it in a Dictionary with character as key and its pixel content as value. And save this data to a file, so that it can be used.
Using the Dataset
Now that we have the captcha character's data in a file, this can be used in other projects that need solving/ image to text capabilities for this captcha.
- Fetch the captcha image for your request.
- De-Noise the image with the same process used in the captcha dataset creation process.
- Crop the de-noised image into its respective characters.
- Load the captcha dataset and compare the image pixel data of the cropped image with the pixel data of all characters present in the dataset. Take a
possible matchvalue for each comparison and in the end the character with maximum value forpossible matchis the most probable/ identified Character.
In my project this probability value for the right comparison was almost always 1 (ranged between 90 - 100% due to noise pixels near character in some cases). Which means it can identify the character with perfect accuracy.
In the above code -
The image is first cropped into individual characters and saved for debug purposes. The data set CaptchaJSON.json is loaded for decoding the saved character images. Since I found that my prediction works with good accuracy (almost 1), if the predicted probability goes below 0.7, this function prints a warning message. (Explaining the snippet, I case you choose to use it in your code).
Conclusion
I have no background in Image Processing and honestly had no idea where to start when I was stuck with this captcha. This was one of the reason why I did not go the ML or tesseract way. Most of the processes there are gibberish to me and poking around the captcha showed that learning such libraries was way too much effort for solving this issue at hand. Anyway, It actually worked quite better than I had expected. I was just hoping for an accuracy of 0.6 - 0.7, ended up getting close to 1.
Thanks for sticking so long and I hope this article gave you a perspective on how to approach solving an image-to-text problem.